Données administratives
La baisse généralisée au niveau européen des taux de réponse1 (Luiten, Hox, and Leeuw 2020; Beck et al. 2022), qui accroît les coûts de collecte et rend plus difficile celle-ci sur certaines sous-populations, notamment les plus jeunes, nécessite de trouver des solutions pour répondre à la demande toujours accrue de statistique officielle.
Comme développé dans l’introduction, les données administratives sont des données de gestion produites par l’administration. Le processus de production statistique, où la collecte de donnée est construite de manière à mesurer le plus objectivement possible un phénomène cible, diffère du processus de production administratif. Pour cette dernière, la donnée est produite de sorte à faciliter la gestion. L’exploitation de celle-ci à des fins de production de statistique ou de recherche n’est pas le moteur de leur construction. L’exploitation de cette donnée est une affaire d’opportunité. Cette perte de contrôle du processus de production, qui fait que l’exploitant de la donnée se retrouve en aval de son processus de production, a tout de même des bénéfices : l’exhaustivité sur une population cible et la plus haute fréquence de ces données. Ceci explique qu’elles deviennent de plus en plus importantes dans la production de statistique officielle.
Ce chapitre revient sur le contexte d’utilisation des données administratives, leurs différences avec d’autres sources de données et les apports de celles-ci à la production de savoir statistique.
Contexte
In this world, nothing is certain except death and taxes.
Benjamin Franklin
Nature des données
Les données statistiques traditionnelles (sondage ou recensement) sont produites pour informer. Cette finalité guide la conception de celles-ci, que ce soit au niveau du design, des concepts mesurés ou des retraitements post-collecte. La logique des données administratives est toute autre. Il s’agit de bases dont la finalité de construction est la gestion, c’est-à-dire l’enregistrement d’événements pour déclencher des actions (remboursement, paiement, etc.).
Cet aspect transactionnel de la donnée adminstrative change ainsi le processus de production. Ces bases sont susceptibles d’être mises à jour à plusieurs échéances. D’abord, leur structure n’est pas figée dans le temps. Selon les événements à enregistrer, la structure du fichier de données évoluera. Par exemple, un nouveau crédit d’impôt amènera à l’ajout d’une catégorie dans les déclarations fiscales ce qui se traduira par un changement du fichier de gestion. A ce premier facteur d’évolution peut s’ajouter des changements à plus brève échéance. La collecte de données administratives est un processus vivant. Les données sont généralement modifiables au cours d’un exercice de gestion voire au-delà. La donnée n’est stabilisée qu’après plusieurs cycles de gestion et sa continuité, au niveau de l’unité statistique, ne va pas de soi. Par exemple, une entreprise changeant d’identifiant SIREN pour une raison liée à un changement administratif (par exemple une fusion) ne sera identifiable dans différents millésimes de données administratives que si on est en mesure de relier les différents identifiants sous lequel elle apparaît.
Les données administratives peuvent provenir de plusieurs origines. Elles sont en premier lieu issues de processus de gestion interne à l’administration concernée. Par exemple, pour être en mesure de gérer les remboursements liés au système de protection sociale français, l’assurance maladie collecte et enregistre de nombreuses informations sur les actes médicaux. Cette collecte est automatisée grâce à la carte vitale et au système d’information de l’assurance maladie ou passe par des déclarations papiers normalisées.
Une seconde source d’origine des données administratives sont les déclarations administratives2 (Rivière 2018). Par exemple, les déclarations fiscales des ménages sont annuelles, avec un calendrier déterminé à l’avance (qui dépend du format, papier ou internet). Ce calendrier inclut d’ailleurs des possibilités allongées de retour sur la donnée fournie. L’obligation de certaines déclarations administratives se traduit par un pouvoir coercitif, pouvant prendre diverses formes, comme celle d’engager des poursuites. Ceci réduit le risque de non-déclaration ou de déclaration faussée mais ne l’annihile pas non plus. Selon la nature de la donnée, ces poursuites peuvent être pénales et les amendes non négligeables. L’existence de ces moyens coercitifs permet d’anticiper une information exhaustive sur la sous-population concernée par la donnée et honnête3.
Si les données administratives sont devenues centrales dans le champ de la production statistique, c’est certes de par leur nature exhaustive mais aussi du fait de leur disponibilité à faible coût marginal. Les données administratives étant collectées et centralisées dans un système informatique à des fins de gestion, leur mise à disposition pour d’autres usages, s’il soulève certains enjeux sur lesquels nous reviendrons comme les questions de confidentialité, est marginalement peu coûteux. L’utilisation de ces données est ainsi une affaire d’opportunité: comme ces données sont disponibles et, sous un certain cadre juridique et technique, peuvent être ré-utilisables à d’autres fins, si elles fournissent une information de qualité, il est utile pour la production statistique de les exploiter.
Quelle différence avec les autres sources de données numériques ?
Cette propriété des données administratives qu’est le coût marginal faible rapproche celles-ci des traces numériques. Les entreprises du numérique ont pu centrer leur modèle économique autour de la collecte et de la valorisation de données justement parce que la collecte de nouvelles informations est d’un coût marginal nul. Il en va de même avec les données de gestion: la collecte d’une information supplémentaire sur une unité ou d’une unité supplémentaire n’est pas coûteuse. Dans le monde de la donnée numérique, il est certes nécessaire d’engager des investissements pour être en mesure de collecter des données de manière massive ou mettre à l’échelle un processus de collecte devenu plus ambitieux que le plan initial mais la donnée marginale ne coûte pas très cher puisque, comme nous allons le voir, la collecte de celle-ci est reportée sur un tiers.
Dès lors, la distinction entre données administratives et données numériques, telles qu’on peut formaliser le buzzword “big-data”, apparaît floue. La distinction correspond en premier lieu à l’origine des données. La donnée administrative est une donnée produite par la sphère administrative. Dans sa nature, son processus de production ne diffère pas de celui de la donnée privée. Dans les deux cas, un acteur effectue une activité (par exemple déclarer quelque chose) et cette activité va être transformée en information plus ou moins normalisée pour intégrer un système d’information et être stockée dans les serveurs d’un acteur centralisateur. Dans les deux cas, la personne dont la donnée a été collectée pourra éventuellement corriger l’information et/ou produire de nouvelles activités.
La différence entre données administratives et données privée est ainsi plutôt une différence de degré que de nature. Les données administratives sont généralement collectées à plus faible fréquence. Par exemple, le rythme de collecte de nombreuses données est annuel pour correspondre aux rythmes des campagnes fiscales. Mais certaines sources sont à des rythmes plus fréquents. Par exemple la DSN, sur laquelle nous reviendrons, est collectée à un rythme mensuel. Certaines données sont mêmes enregistrées à des rythmes qui n’ont pas grand chose à envier avec les traces numériques du big data. Par exemple, les systèmes d’information SIVIC et SIDEP, respectivement celui de suivi des entrées à l’hôpital des personnes malades du Covid et celui des tests, étaient mis à jour quotidiennement. De même, le système d’information de l’assurance maladie est mis à jour en continu en fonction des nouveaux événements qui appellent un remboursement. Bien qu’on n’associe pas forcément les données administratives avec une collecte en temps réel, il ne s’agit ainsi pas d’un critère les discriminant vis à vis des traces numériques.
La différence principale, peut-être, entre les données administratives et les données privées est que pour les premières, le champ est connu par le fait que celles-ci sont issues d’une collecte d’une population bien ciblée. Comme indiqué précédemment, comme la collecte de données administrative est souvent assortie de prérogatives légales, la population cible est généralement bien identifiée. Dans le monde de la donnée privée, comme c’est l’activité qui génère la donnée, le champ dépend de la base d’utilisateurs. Selon le type de données, celle-ci peut être plus ou moins large. Même parmi les données privées où les populations sont les plus larges, la couverture de la population n’est pas parfaite. Par exemple, les smartphones sont largement partagés dans la population. Néanmoins, cette technologie a un moindre taux de pénétration dans certaines population, notamment les plus agées. De plus, les opérateurs ont des parts de marché potentiellement hétérogènes (en fonction de critères d’âge ou territoriaux). Pour les opérateurs, il est difficile d’évaluer le champ de leur clientèle puisque cette information nécessite une enquête, et ainsi souffre de taux de réponse imparfaits ou de réponses incorrectes. Le champ est donc incertain puisqu’il n’est pas possible pour les producteurs de données privées d’apparier de manière automatique ces données avec les données administratives. Même s’il n’est pas toujours possible d’apparier des données administratives entre elles pour des raisons légales, le fait de fournir des informations communes dans différentes sources (état civil voire NIR) à un même acteur (l’Etat), facilite l’association entre les sources lorsque celle-ci est autorisée.
Les 5V du big-data, initialement listés dans un rapport de MacKinsey, ne sont pas l’apanage des données privées. Il y a peut-être une différence de degré avec le big-data mais certainement pas de nature:
- Volume: certaines données administratives représentent des volumes conséquents. La DSN représente ainsi plus d’1To de données par an ;
- Vélocité: certaines données, notamment celles de l’assurance maladie, sont à haute fréquence ;
- Variété: l’Etat collecte et exploite des données de natures très différentes ;
- Véracité: les données collectées par l’Etat ne sont pas à l’abri d’erreurs mais ces dernières, qu’elles soient volontaires ou non, pouvant être couteuses, les données sont normalement de meilleure qualité que celles auto-déclarées sans contrôle ex-post ;
- Valeur: les données collectées par l’Etat sont d’une grande valeur même si elles ne sont pas monétisées. La valorisation par l’Etat n’est bien-sûr pas individuelle mais la collecte de données qui sont ensuite agrégées permet de créer une statistique publique, qui est un bien public, sans valeur de marché mais avec une valeur sociale.
Finalement, il y a peu de différence entre les données administratives et certaines données privées disponibles sous forme structurée. Par exemple, les données générées par les paiements par cartes bancaires (données du GIE CB) ne sont pas d’une nature très différente de données administratives. Comme celles-ci, il s’agit de données structurées issues d’un organisme centralisateur (le GIE CB) et mises à disposition consolidées pour la statistique publique.
Une donnée plus sensible
L’aspect exhaustif, sur un certain champ d’unités et d’informations de gestion, des données administratives peut les rendre, au niveau individuel, assez sensibles. La question de la confidentialité et de la sensibilité des données fournie à l’administration n’est pas nouvelle, il s’agit de la raison d’être du secret statistique défini dans l’une des lois les plus importantes de la statistique publique, à savoir la loi de 1951. Les informations fournies dans le cadre de certaines enquêtes peuvent être sensibles (informations sur le revenu ou le patrimoine, la santé, l’appartenance à certains groupes sociaux…). Cependant, l’aspect non exhaustif des enquêtes rend plus difficile la réidentification après la phase d’anonymisation. Avec les données administratives, l’information fournie peut parfois être moins précise mais le caractère exhaustif de celles-ci fait qu’en combinant plusieurs sources de données la réindentification est facilitée.
La question de la confidentialité est donc, au même titre que pour les données privées, devenu un enjeu dans le domaine des données administratives. Il est à noter que par rapport aux données privées cette question ne se pose pas au même niveau. Au niveau de la collecte de données, c’est-à-dire de la transformation d’une activité en donnée de gestion, là où l’utilisateur d’un service numérique bénéficie d’une relative liberté sur le choix des données collectées du fait du RGPD, ce n’est pas le cas pour l’utilisateur d’un service géré par l’Etat. Ce privilège de l’Etat s’appuie sur des décrets qui définissent des missions de service public. Cependant, au niveau des traitements mis en oeuvre, du stockage puis de la diffusion de la donnée, des conditions restrictives s’appliquent aussi à l’Etat. Exemple: SNDS.
Cet encadré résume des éléments juridiques listés par Isnard (2018).
Les membres du service statistique public (SSP) bénéficient d’une disposition importante qui facilite énormément le travail du statisticien. Ce sont les seuls organismes à pouvoir mettre en œuvre l’article 7bis de la loi de 1951. Cet article leur permet de se faire communiquer, à des fins d’élaboration de statistiques publiques, tout fichier de gestion d’une administration ou d’une personne privée gérant un service public, dès lors que le Conseil national de l’information statistique a été consulté et que la demande émane du ministre chargé de l’économie (en pratique du directeur général de l’Insee). Cette mesure, insérée dans la loi du 7 juin 1951 par la loi du 26 décembre 1986, a permis une exploitation large des données administratives et ainsi un allègement de la charge de réponse aux enquêtes.
L’utilisation de déclarations ou de sources administratives à des fins statistiques est préconisée par le code de bonnes pratiques de la statistique européenne dans le but d’alléger la charge statistique des déclarants. En France, ceci est rendu possible par la loi de 1951 relative à l’obligation, à la coordination et au secret en matière de statistique et a été réaffirmé récemment par la loi pour une République numérique (2016).
Processus de production
Le processus de production de la donnée administrative est différent de celui de la donnée traditionnelle. La différence principale est la place centrale d’une autorité gestionnaire, qui centralise la donnée, dans le modèle de production des données administratives (Rivière 2018). Cet acteur doit être distingué de l’administration qui exploite le flux, que ce soit à des fins de gestion ou d’exploitation statistique.
La Table 1 donne quelques exemples de plateformes centralisatrices. Ces dernières ne se contentent pas de centraliser ou mettre à disposition la donnée, elles ont aussi en charge la normalisation de celle-ci à partir de systèmes d’informations divers. La normalisation est un enjeu majeur car elle seule permet l’exploitation des données: la collecte étant en général réalisée automatiquement via des auto-déclarations, les plateformes centralisatrices récupèrent des informations aux contenus hétérogènes.
| Donnée | Autorité centralisatrice |
|---|---|
| DSN | Gip-MDS |
| Données hospitalières | ATIH-10 |
| SI gestion des eaux | SANDRE12 |
La Figure 1 résume la place du GIP-MDS dans le processus de production de la DSN:
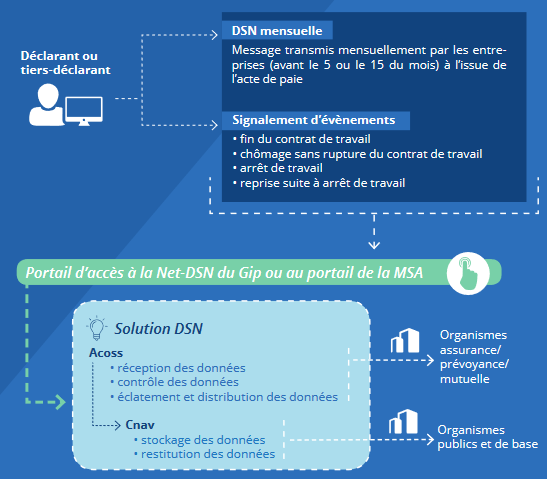
Usage de la donnée administrative
L’usage de ces données est de deux nature: l’usage à des fins de gestion (la finalité pour laquelle elles sont construites) et l’usage à des fins d’analyse (la finalité fortuite). Ces peut aller au-delà de l’administration concernée. Par exemple, la déclaration sociale nominative n’est pas utilisée exclusivement par le Ministère du Travail mais aussi par la DGFIP, les institutions de prévoyance, les organismes de retraite, l’Acoss, pour leurs propres usages de gestion ; les données de SIRENE servent de référence, de preuve pour les entreprises, elles sont utilisées par les chambres de commerce et d’industrie ou par les greffes des tribunaux de commerce (Rivière 2018).
Un usage accru pour apparier des sources
Certaines sources administratives ont un rôle particulier dans le processus de production statistique car elle permettent d’identifier des unités statistiques dans plusieurs sources. Le Répertoire national d’identification des personnes physiques (RNIPP), le répertoire Sirene pour les entreprises ou encore XXX pour les logements, sont des sources qui permettent de relier des unités statistiques entre plusieurs sources. On parle d’appariements pour désigner ce type d’opérations où plusieurs sources de données sont associées grâce à une information commune. Cela peut se faire sur la base d’une information exacte, en général un identifiant unique fourni par un des référentiels, ou de manière floue à partir d’informations non uniques mais qui, combinées, peuvent aider à identifier une unité (nom, raison sociale d’une entreprise, adresse, etc.).
Ces répertoires administratifs sont ainsi des sources devenues centrales dans le processus de production statistique. Ils permettent d’enrichir d’autres sources administratives, ou des enquêtes, d’informations administratives. Ces dernières peuvent ainsi permettre d’alléger certains questionnaires d’enquêtes ou de concentrer ceux-ci sur des informations qui ne sont pas disponibles dans les sources administratives.
Un enjeu fort existe autour de la production d’un code statistique non signifiant (CSNS) pour les besoins de mise en œuvre de traitements à finalité de statistique publique impliquant le numéro de sécurité sociale (NIR) ou des traits d’identité, en particulier les appariements au sein du Service statistique publique. La version finale est prévue pour la fin de l’année 2022.
Un changement de la place de l’analyste de la donnée
Cette situation change la place du statisticien dans le processus de production de la statistique officielle. Il convient de transformer en aval les données pour répondre aux besoins de l’analyse statistique. Cela implique un contrôle qualité ex-post, éventuellement un travail de reconstitution et de consolidation.
Cette situation change également la place des chercheurs dans le processus de production de la donnée. Comme le statisticien, le chercheur n’est plus associé à l’amont de la production de données. Cependant celui-ci est, généralement, encore plus en aval que le statisticien public. Il reçoit les données généralement consolidées, anonymisées et éventuellement appariées entre différentes sources. A cet égard, les données administratives scandinaves sont parmi les données les plus utilisées par les chercheurs sur le marché du travail car elles constituent une source depuis longtemps centralisée et mise à disposition de manière anonymisée.
En conclusion, quels avantages et inconvénients ?
La production et l’usage de données administratives se sont généralisés. La numérisation croissante de l’économie est amené à confirmer cette tendance. L’utilisation par la statistique publique de données privées, sous leur forme structurée, n’est qu’un prolongement de cette dynamique. Ces dernières permettent d’enrichir l’information dont dispose l’administration avec des informations collectées dans le cadre d’activités économiques détachées de l’administration.
Les avantages des données administratives sont multiples. En premier lieu, la collecte automatisée de celle-ci, associée à un pouvoir public coercitif, permet d’atteindre sur un champ d’unités statistiques bien définies (usuellement par le biais d’un décret), une forme d’exhaustivité. Cette dernière permet de construire des statistiques plus fines. Si aujourd’hui il est possible pour des chercheurs de zoomer sur le très haut de la distribution de revenu (voir les travaux de Piketty), c’est parce que l’aspect exhaustif des données permet d’avoir des groupements suffisamment nombreux pour assurer la confidentialité de ces groupes.
Une fois payé le coût d’investissement pour automatiser la production statistique à partir de données de gestion, les données administratives ouvrent la voie à la production à plus haute fréquence de statistiques officielles. La production annuelle ou infra-annuelle de statistiques n’est possible qu’avec un nombre restreint d’enquêtes - dans la plupart des cas, les résultats d’enquêtes sont connus avec du retard. La publication quotidienne par le service statistique du Ministère de la Santé (la DREES) et Santé Publique France d’indicateurs sur la pandémie est un bon exemple de l’intérêt de ces données. Ces dernières ont permis un suivi très fin par la puissance publique mais aussi par la société civile des évolutions de l’épidémie.
Un autre avantage des données administratives est que les informations qui sont disponibles dans celles-ci sont certes diverses (nous reviendrons sur cela dans le prochain chapitre à travers quelques exemples) mais elles sont, sur certains champs, très fiables. Elles souffrent normalement moins de biais de réponses même si elles n’en sont pas exemptées (les déclarations erronées à l’administration fiscale existent, qu’il s’agisse d’un comportement volontaire ou non).
Ces données soulèvent de nouveaux défis pour la statistique publique. En premier lieu, elles amènent à redéfinir le rôle du métier dans le processus de production de la donnée. Ceci est vrai dans le monde de la donnée administrative mais aussi dans le domaine des données privées. Comme l’utilisateur de données ne contrôle pas le champ ou la définition du concept mesuré, c’est le concentrateur, cet acteur dont l’activité est spécialisée autour de la collecte et de la gestion du flux, qui intervient à cet étape. Il peut ainsi être amené à faire évoluer le champ, la définition du phénomène mesuré ou encore le formulaire sans que l’analyste de données n’ait son mot à dire. Pour reprendre l’exemple des données quotidiennes, l’apparition de variants à plusieurs reprises a amené à des évolutions, parfois sans préavis, du type de donnée collectée, enregistrée. Les données déjà collectées n’ayant pas vocation à intégrer ces informations qui n’avaient pas de sens au moment de la collecte, c’est à l’analyste de données de faire des choix méthodologiques pour reconstruire une série cohérente. Le statisticien, parce qu’il intervient plus en aval, change donc de rôle. Les données administratives n’étant pas construites pour mesurer un phénomène qui a du sens pour le statisticien public (ou l’analyste de la donnée privée), c’est à lui de reconstruire à partir de l’information de gestion la réalité statistique derrière (Salgado and Oancea 2020). Le travail de l’analyse de données va au donc au delà de la simple reconstruction de variable, ou du contrôle qualité, il est également nécessaire de réfléchir au concept mesuré pour ne pas construire d’“artefact”, au sens de Bourdieu. Cette problématique se pose, de la même manière, à la recherche et à l’exploitation de données privées.
References
Footnotes
Par exemple, le taux de réponse a baissé pour l’enquête en face-à-face Cadre de vie et sécurité de 72 % à 66 % entre 2012 et 2021. En ce qui concerne SRCV (Statistiques sur les ressources et les conditions de vie), le taux de réponse est passé de 85 % à 80 % entre 2010 et 2019. Des événements ponctuels comme la crise du Covid-19 peuvent de plus avoir des effets très forts sur le taux de réponse. Par exemple, en 2020, à la date du 23 avril, le taux de réponse à l’enquête sur la production industrielle en mars, qui sert d’indicateur avancé de l’activité économique, était inférieur d’environ 20 points de pourcentage à ce qui est observé lors d’un mois habituel (voir blog de l’Insee).↩︎
Obligation est faite à un certain nombre d’entités (individus, entreprises, organismes publics) de fournir des informations respectant une certaine forme, selon certaines modalités (internet, papier) et temporalités.↩︎
Certaines enquêtes, reconnues d’utilité publique, comme l’enquête emploi, le recensement ou encore l’enquête ressources et conditions de vie (SRCV), sont obligatoires. Bien que cela permette d’avoir des taux de réponse élevés, cela n’assure pas un taux de 100%. Comme cela a été évoqué précédemment, le taux de réponse de SRCV est par exemple passé de 85 % à 80 % entre 2010 et 2019. Pour plus d’informations sur les enquêtes obligatoires, voir la description du CNIS et la liste des enquêtes concernées parmi les enquêtes auprès des particuliers.↩︎